Contenidos
- Introducción
- Primer ejemplo: una postal
- Segundo ejemplo
- Conclusiones
- Epílogo. Transformaciones básicas sin XSLT
- Referencias recomendadas
- Notas
Introducción
Esta es la segunda parte de la lección sobre codificación de textos en el lenguaje de marcado TEI. La primera consistió en una breve introducción al concepto de codificación y su importancia en las humanidades digitales, así como a los documentos XML y TEI.
Con el objetivo de ilustrar las posibilidades que ofrece TEI, en esta parte estudiaremos en detalle dos ejemplos de codificación de textos breves.
Ahora bien, aunque en principio las dos lecciones son independientes, en el sentido en que pueden comprenderse la una sin la otra, es recomendable revisar la primera parte antes de seguir con los ejemplos examinados en esta.
Software que usaremos
Al igual que en la primera parte, utilizaremos el editor de texto Visual Studio Code (VS Code, más brevemente) y el “plugin” o extensión XML Complete. Los detalles de la instalación de lo anterior están disponibles en la primera parte de la lección.
Primer ejemplo: una postal
Consideremos la siguiente postal de Federico García Lorca:
{kind=link}

Postal de Federico García Lorca
Las postales tienen dos caras: la frontal, que contiene un imagen, y la de atrás, que contiene la dirección, la estampilla y el texto.
En TEI podríamos usar dos elementos <div> (“división”) para cada cara.
De hecho, podríamos usar el atributo @type (“tipo”)1 para distinguirlas (con los valores recto y verso respectivamente), así:
<text>
<body>
<div type="recto">
<!-- aquí iría la cara frontal -->
</div>
<div type="verso">
<!-- aquí iría la cara de atrás -->
</div>
</body>
</text>
Para este primer ejemplo trabajaremos con la parte de atrás. La parte frontal de una postal contiene una imagen y no podríamos codificarla adecuadamente a menos que contuviera algún texto. Podemos identificar al menos cuatro partes estructurales en nuestra postal:
- El mensaje
- Los saludos
- La dirección
- Las estampillas
Recordemos que nuestra codificación no debe ser una representación gráfica del texto —es decir, no debe simular cómo se ve—, sino una representación semántica.2
En ese sentido, podemos usar cuatro elementos <div> para cada una de las partes de nuestra postal, sin tener en cuenta su ubicación espacial exacta.
Si dicha ubicación nos interesara podríamos valernos de los elementos que TEI ofrece para codificar facsímiles digitales
(por ahora los pasaremos por alto). Podemos empezar entonces con la siguiente estructura:
<?xml version="1.0" encoding="UTF-8"?>
<TEI xmlns="http://www.tei-c.org/ns/1.0">
<teiHeader>
<fileDesc>
<titleStmt>
<title>Postal a Antonio Luna del 14 de mayo de 1926</title>
<author>Federico García Lorca</author>
</titleStmt>
<publicationStmt>
<publisher>Nicolás Vaughan</publisher>
<pubPlace>Bogotá, Colombia</pubPlace>
<date>2021</date>
<availability>
<p>Esta es una obra de acceso abierto licenciada bajo una licencia Creative Commons Attribution 4.0 International.</p>
</availability>
</publicationStmt>
<sourceDesc>
<biblStruct>
<monogr>
<author>Federico García Lorca</author>
<title>Postal a Antonio Luna</title>
<imprint>
<pubPlace>Cadaqués, Barcelona</pubPlace>
<date>1926</date>
</imprint>
</monogr>
<ref target="https://commons.wikimedia.org/wiki/File:Postal_de_Federico_a_Antonio_de_Luna.jpg"/>
</biblStruct>
</sourceDesc>
</fileDesc>
</teiHeader>
<text>
<body>
<div type="saludos">
<!-- aquí va el texto de los saludos -->
</div>
<div type="mensaje">
<!-- aquí va el texto del mensaje -->
</div>
<div type="dirección">
<!-- aquí va el texto de la dirección-->
</div>
<div type="estampillas">
<!-- aquí va el texto de las estamillas y los sellos postales -->
</div>
</body>
</text>
</TEI>
El <teiHeader> de este código contiene los datos básicos de la postal (disponible libremente en la página de Wikimedia Commons), así como los metadatos de la codificación.
En <text> (texto) hemos incluido los tres elementos <div> correspondientes a las partes que hemos identificado.
Asimismo, hemos asignado los valores saludos, mensaje, dirección y estampillas (así, en español) al atributo @type.
El uso de este atributo es opcional; el documento bien podría no tenerlo y seguir siendo válido.
Sin embargo, este atributo nos sirve para distinguir los diferentes tipos de <div> en nuestro documento.
Vale la pena que los codifiquemos —tal como lo hicimos anteriormente— solo si esperamos eventualmente valernos de esa información para algo en concreto, por ejemplo, si quieremos extraer solo la información de los sellos postales.
En lugar del atributo @type, también es usual utilizar el atributo global @n que sirve para enumerar los elementos de un mismo tipo.
Por ejemplo:
<text>
<body>
<div n="1">
<!-- aquí va el texto de los saludos -->
</div>
<div n="2">
<!-- aquí va el texto del mensaje -->
</div>
<div n="3">
<!-- aquí va el texto de la dirección-->
</div>
<div n="4">
<!-- aquí va el texto de las estamillas y los sellos postales -->
</div>
</body>
</text>
Sin embargo, para nuestros fines el atributo @type estará bien.
Continuemos.
Primer <div>: los saludos
Puesto que este es un texto manuscrito, será importante que tengamos en cuenta los saltos de línea.
Usaremos para ello el elemento de autocerrado <lb/> (“line break” o salto de línea).3
Empecemos, pues, a codificar el primer <div>:
<div type="saludos">
<p>
<lb n="1"/>Saludos de Salvador Da.
</p>
</div>
Si nos fijamos en el código anterior, podremos notar tres cosas:
Primero, el hijo inmediato del <div> es un elemento de párrafo <p>.
La razón de esto es que, de acuerdo con las reglas semánticas de TEI para los <div>, estos elementos no pueden contener texto plano inmediatamente, sino que deben contener otros elementos (por ejemplo <p>).4
Segundo, el elemento vacío <lb/> va al principio de la línea que identifica y no al final como podría esperarse.
Como mencionamos arriba, este tipo de elementos —denominados “hitos” o “marcadores” (“milestones”)— sirven para indicar lugares liminales en el texto (saltos de línea, en este caso, pero también saltos de página o de columna, entre otros).
Tercero, los saludos nombran a “Salvador Da.” (seguramente Salvador Dalí).
Haremos entonces dos cosas.
Por un lado, pondremos dicho nombre en el contenido de un elemento <persName>.
Podríamos hacerlo también en un elemento <name> (nombre), aunque la elección de <persName> (“person name”, nombre de persona) es semánticamente más precisa.
<div type="saludos">
<p>
<lb n="1"/>Saludos de <persName>Salvador Da.</persName>
</p>
</div>
Por otro lado, “Da.” (incluido el punto) es una abreviatura para “Dalí”.
TEI nos ofrece el elemento <abbr> (“abbreviation”, abreviatura) para codificar abreviaturas
y el elemento <expan> (“expansion”, expansión) para hacer otro tanto con sus expansiones.
El conjunto de una abreviatura y su expansión deben ponerse dentro de un elemento <choice> (elección) a fin de conectarlos, así:
<choice>
<abbr></abbr>
<expan></expan>
</choice>
Todo el <div> quedaría entonces así:
<div type="saludos">
<p>
<lb n="1"/>Saludos de
<persName>
Salvador
<choice>
<abbr>Da.</abbr>
<expan>Dalí</expan>
</choice>
</persName>
</p>
</div>
De nuevo, los saltos de líneas en el código son irrelevantes y los incluimos aquí para facilitar su legilibilidad.
Ahora bien, en la imagen de nuestra postal el saludo aparece subrayado.
¿Cuál es el propósito de dicho subrayado?
En mi opinión, la raya solo sirve aquí para separar este texto del resto.
Su función es estructural, no enfática.
Por esa razón no la vamos a codificar; simplemente incluimos estos “saludos” en un <div> independiente.
Sin embargo, si opináramos que su función es enfática, podríamos usar el elemento <hi> (“highlight”, resaltado), con el atributo @rend (“rendition”, representación) y el valor underline para codificar tal uso enfático, así:
<div type="saludos">
<p>
<hi rend="underline">
<lb n="1"/>Saludos de
<persName>
Salvador
<choice>
<abbr>Da.</abbr>
<expan>Dalí</expan>
</choice>
</persName>
</hi>
</p>
</div>
Segundo <div>: el mensaje
Continuemos ahora con el texto del mensaje, que va dentro de nuestro segundo <div>.
Transcribamos las trece líneas del texto y codifiquémoslas inicialmente:
<div type="mensaje">
<p>
<lb n="1"/>Querido Antonito: Enmedio de
<lb n="2"/>un ambiente delicioso de mar,
<lb n="3"/>fotografos y cuadros cubistas
<lb n="4"/>te saludo y te abrazo.
<lb n="5"/>Dali y yo preparamos una
<lb n="6"/>cosa que estará moll bé.
<lb n="7"/>Una cosa moll bonic.
<lb n="8"/>Sin darme cuenta me he
<lb n="9"/>impuesto en el Catalan.
<lb n="10"/>Adios Antonio. Saluda a tu padre.
<lb n="11"/>Y saludate tu con mi mejor inalterable
<lb n="12"/>amistad. ¡Has visto lo que han hecho con Paquito! (Silencio)
<lb n="13"/>Federico
</p>
</div>
Notemos que no hemos corregido o “normalizado” la ortografía en nuestra transcripción del texto.
Esto es importante porque hemos querido capturar al texto mismo, sin mayores intervenciones editoriales, lo que se denomina una “transcripción diplomática”.
Sin embargo, en el presente caso nos interesa también intervenir editorialmente el texto, normalizando su ortografía.
Para ello usaremos el elemento <orig> (“original form”, forma original) para codificar el texto original (antes de la normalización),
y el elemento <reg> (“regularization”, regularización) para codificar el texto regularizado o normalizado.
Como con las abreviaturas y sus expansiones, debemos incluir la pareja de elementos en un elemento <choice>:
<choice>
<orig></orig>
<reg></reg>
</choice>
Normalicemos entonces todo lo que lo requiera:
<div type="mensaje">
<p>
<lb n="1"/>Querido Antonito:
<choice>
<orig>Enmedio</orig>
<reg>En medio</reg>
</choice>
de
<lb n="2"/>un ambiente delicioso de mar,
<lb n="3"/>
<choice>
<orig>fotografos</orig>
<reg>fotógrafos</reg>
</choice>
y cuadros cubistas
<lb n="4"/>te saludo y te abrazo.
<lb n="5"/>
<choice>
<orig>Dali</orig>
<reg>Dalí</reg>
</choice>
y yo preparamos una
<lb n="6"/>cosa que estará moll bé.
<lb n="7"/>Una cosa moll bonic.
<lb n="8"/>Sin darme cuenta me he
<lb n="9"/>impuesto en el
<choice>
<orig>Catalan</orig>
<reg>catalán</reg>
</choice>.
<lb n="10"/>
<choice>
<orig>Adios</orig>
<reg>Adiós</reg>
</choice>
Antonio. Saluda a tu padre.
<lb n="11"/>Y
<choice>
<orig>saludate tu</orig>
<reg>salúdate tú</reg>
</choice>
con mi mejor inalterable
<lb n="12"/>amistad. ¡Has visto lo que han hecho con Paquito! (Silencio)
<lb n="13"/>Federico
</p>
</div>
Tenemos también varios nombres propios: “Antonito”, “Dalí”, “Antonio”, “Paquito” y “Federico”.
Codifiquémoslos ahora con ayuda del elemento <persName>:
<div type="mensaje">
<p>
<lb n="1"/>Querido <persName>Antonito</persName>:
<choice>
<orig>Enmedio</orig>
<reg>En medio</reg>
</choice>
de
<lb n="2"/>un ambiente delicioso de mar,
<lb n="3"/>
<choice>
<orig>fotografos</orig>
<reg>fotógrafos</reg>
</choice>
y cuadros cubistas
<lb n="4"/>te saludo y te abrazo.
<lb n="5"/>
<persName>
<choice>
<orig>Dali</orig>
<reg>Dalí</reg>
</choice>
</persName>
y yo preparamos una
<lb n="6"/>cosa que estará moll bé.
<lb n="7"/>Una cosa moll bonic.
<lb n="8"/>Sin darme cuenta me he
<lb n="9"/>impuesto en el
<choice>
<orig>Catalan</orig>
<reg>catalán</reg>
</choice>.
<lb n="10"/>
<choice>
<orig>Adios</orig>
<reg>Adiós</reg>
</choice>
<persName>Antonio</persName>. Saluda a tu padre.
<lb n="11"/>Y
<choice>
<orig>saludate tu</orig>
<reg>salúdate tú</reg>
</choice>
con mi mejor inalterable
<lb n="12"/>amistad. ¡Has visto lo que han hecho con <persName>Paquito</persName>! (Silencio)
<lb n="13"/><persName>Federico</persName>
</p>
</div>
Nótese que en el caso de “Dalí” todo el elemento <persName> contiene a la pareja normalizada.
<persName>
<choice>
<orig>Dali</orig>
<reg>Dalí</reg>
</choice>
</persName>
Aunque no es obligatorio, sí es recomendable hacer explícito el idioma del texto principal, en este caso español.
Esto lo hacemos con el atributo de XML @xml:lang y el valor spa en el elemento <text>:
<text xml:lang="spa">
<!-- aquí va todo el texto del documento -->
</text>
Las líneas 6 y 7 (en el texto de la imagen) contienen texto en otra lengua, el catalán.
TEI nos permite codificar el cambio de idioma con el elemento <foreign>.
Para identificar el idioma usamos el atributo de XML @xml:lang con el valor cat.
Esas dos líneas quedarán así:
<lb n="6"/>cosa que estará <foreign xml:lang="cat">moll bé</foreign>.
<lb n="7"/>Una cosa <foreign xml:lang="cat">moll bonic</foreign>.
Curiosamente, García Lorca escribió “moll” en ambos casos, cuando lo correcto en el catalán sería “molt”.5
En ese caso podemos anotar el “error” usando los elementos <sic> (así, en latín), para indicar el original, y <corr> (“correction”, corrección) para indicar nuestra corrección.
Ambos elementos deben estar encerrados en un elemento <choice>, a fin de que el procesador de XML entienda que constituyen una unidad.
Así pues, el código anterior quedaría así:
<lb n="6"/>cosa que estará <foreign xml:lang="cat"><choice><sic>moll</sic><corr>molt</corr></choice> bé</foreign>.
<lb n="7"/>Una cosa <foreign xml:lang="cat"><choice><sic>moll</sic><corr>molt</corr></choice> bonic</foreign>.
¿Qué más podemos codificar aquí?
Primero, notemos que hace falta una coma en la línea 3 (en el texto de la imagen).
Introducirla en nuestro documento es también una forma de intervención editorial, para la que nuevamente usaremos el elemento <corr> esta vez solo:
y cuadros cubistas<corr>,</corr>
Eso significa que el editor —o codificador, en este caso nosotros— ha introducido , en el texto.
Nótese que no hemos dejado un espacio en blanco entre cubistas y <corr>,</corr>.
Por otro lado, notemos que “Federico”, en la línea 13 (en el texto de la imagen), es la firma del autor de la postal.
TEI tiene el elemento <signed> (signature, “firma”) para codificarlo.
Si leemos la documentación de TEI, este elemento no puede ser un hijo de <p> sino solo de los siguientes elementos:
Contained by:
core: lg list
drama: castList epilogue performance prologue
figures: figure table
textstructure: back body closer div div1 div2 div3 div4 div5 div6 div7 front group opener postscript
Aquí usaremos el elemento <closer> (cierre), que codifica el cierre de una carta o postal.
Lo que haremos ahora será sacar el código <persName>Federico</persName> del elemento <p> que lo contiene, lo meteremos en un elemento <signed> y, finalmente, lo incluiremos en un nuevo elemento <closer>:
<closer>
<signed><persName>Federico</persName></signed>
</closer>
Ahora debemos eliminar el <lb n="13"/> puesto que los hitos <lb/> hacen parte del elemento <p>, es decir, son líneas de un párrafo.
Como hemos sacado la firma del párrafo y hemos creado una nueva división (<closer>), ya no es necesario que introduzcamos un nuevo salto de línea.
Dicho con otras palabras, este salto de línea cumple una función estructural, al igual que el subrayado de los “saludos” y en la firma misma.
Sin embargo, si alguien quisiera introducir el <lb n="13"/>, bien podría hacerlo antes del <signed>. TEI no lo prohíbe.
Solo nos queda una cosa por codificar en el mensaje de la postal.
La palabra “inalterable” (en la línea 11) está subrayada.
A diferencia de los “saludos” y de la firma, la función del subrayado parece ser en este caso de énfasis.
Usaremos el elemento <hi> con el atributo @rend y el valor underline (subrayado) para codificarlo:
con mi mejor <hi rend="underline">inalterable</hi>
Tercer <div>: la dirección
TEI nos ofrece el elemento <address> (dirección), compuesto de varios elementos <addrLine> (“address line”, línea de dirección), para codificar esta información.
De acuerdo con la documentación de TEI, <address> debe estar contenido en un elemento <opener> (apertura), que sirve para codificar el inicio (“opener”) de una carta o postal.
Nuestro código será entonces el siguiente:
<div type="dirección">
<opener>
<address>
<addrLine>Sr D. Antonio Luna</addrLine>
<addrLine>Acera de Dairo 62</addrLine>
<addrLine>Granada</addrLine>
</address>
</opener>
</div>
Podemos hacer varias cosas más.
Primero, vamos a expandir las abreviaturas “Sr” y “D.” a “Señor” y “Don”, respectivamente.
Segundo, añadiremos el punto faltante en “Sr” con un elemento <corr>, al igual que hicimos arriba con la coma faltante.
Tercero, vamos a codificar “Antonio Luna” como un nombre de persona, con ayuda del elemento <persName>.
Y, cuarto, vamos codificar “Granada” como un nombre de lugar, con ayuda del elemento <placeName> (nombre de lugar).
Finalmente, en la segunda línea de la dirección, la caligrafía no es del todo clara —al menos para mí—.
¿Dice “Dairo” o “Darío”?
Para casos de ilegilibilidad (o dificultad para leer), TEI nos ofrece varias opciones.
Una es usar el elemento <unclear> (confuso) para encerrar el texto involucrado.
Otra es usar el atributo @cert (certeza), con los valores low, mid o high (baja, media o alta), para indicar el grado de certeza que tiene quien transcribe o edita con respecto a un cierto texto.
Este atributo se incluye en el elemento inmediatamente superior, en este caso el segundo <addrLine>.
Como el texto dudoso no es toda la línea sino solo una palabra, lo más conveniente aquí es usar la opción de <unclear>.
El código completo quedaría así:
<div type="dirección">
<opener>
<address>
<addrLine>
<choice>
<abbr>
Sr<corr>.</corr>
</abbr>
<expan>Señor</expan>
</choice>
<choice>
<abbr>D.</abbr>
<expan>Don</expan>
</choice>
<persName>Antonio Luna</persName>
</addrLine>
<addrLine>
Acera de <unclear>Dairo</unclear> 62
</addrLine>
<addrLine>
<placeName>Granada</placeName>
</addrLine>
</address>
</opener>
</div>
Cuarto <div>: los sellos
El último <div> contiene los sellos postales y demás información impresa.
Aquí tenemos tres textos: “TARJETA POSTAL”, “CORRESPONDENCIA” y un sello parcialmente legible que quizás diga “BARCELONA”.
Para ellos usaremos el elemento <stamp> (sello) de TEI.
Según la documentación, puede ir incluido —entre otras posibilidades— en un elemento <ab> (“anonymous block”, bloque anónimo).
Asimismo, encima del sello hallamos un pedazo de una estampilla verde.
Como no podemos descifrar su contenido, no podemos codificar nada de él.
La opción más común sería excluirlo por completo del documento TEI.
Otra opción sería usar el elemento <gap> (brecha) para indicar una laguna en el texto.
Como no tiene contenido (pues no lo conocemos), podemos usar la forma abreviada <gap/>.3
El código completo sería:
<div type="estampillas">
<ab>
<stamp>Tarjeta Postal</stamp>
<stamp>Correspondencia</stamp>
<stamp><unclear>Barcelona</unclear></stamp>
<stamp><gap/></stamp>
</ab>
</div>
Como puede verse, hemos decidido no transcribir en mayúsculas estos textos puesto que su representación visual es irrelevante para su contenido.2
Código completo del documento
El código completo del documento TEI de la postal es el siguiente:
<?xml version="1.0" encoding="UTF-8"?>
<TEI xmlns="http://www.tei-c.org/ns/1.0">
<teiHeader>
<fileDesc>
<titleStmt>
<title>Postal a Antonio Luna del 14 de mayo de 1926</title>
<author>Federico García Lorca</author>
</titleStmt>
<publicationStmt>
<publisher>Nicolás Vaughan</publisher>
<pubPlace>Bogotá, Colombia</pubPlace>
<date>2021</date>
<availability>
<p>Esta es una obra de acceso abierto licenciada bajo una licencia Creative Commons Attribution 4.0 International.</p>
</availability>
</publicationStmt>
<sourceDesc>
<biblStruct>
<monogr>
<author>Federico García Lorca</author>
<title>Postal a Antonio Luna</title>
<imprint>
<pubPlace>Cadaqués, Barcelona</pubPlace>
<date>1926</date>
</imprint>
</monogr>
<ref target="https://commons.wikimedia.org/wiki/File:Postal_de_Federico_a_Antonio_de_Luna.jpg"/>
</biblStruct>
</sourceDesc>
</fileDesc>
</teiHeader>
<text xml:lang="spa">
<body>
<div type="saludos">
<p>
<lb n="1"/>Saludos de
<persName>
Salvador
<choice>
<abbr>Da.</abbr>
<expan>Dalí</expan>
</choice>
</persName>
</p>
</div>
<div type="mensaje">
<p>
<lb n="1"/>Querido <persName>Antonito</persName>:
<choice>
<orig>Enmedio</orig>
<reg>En medio</reg>
</choice>
de
<lb n="2"/>un ambiente delicioso de mar,
<lb n="3"/>
<choice>
<orig>fotografos</orig>
<reg>fotógrafos</reg>
</choice>
y cuadros cubistas<corr>,</corr>
<lb n="4"/>te saludo y te abrazo.
<lb n="5"/>
<persName>
<choice>
<orig>Dali</orig>
<reg>Dalí</reg>
</choice>
</persName>
y yo preparamos una
<lb n="6"/>cosa que estará <foreign xml:lang="cat"><choice><sic>moll</sic><corr>molt</corr></choice> bé</foreign>.
<lb n="7"/>Una cosa <foreign xml:lang="cat"><choice><sic>moll</sic><corr>molt</corr></choice> bonic</foreign>.
<lb n="8"/>Sin darme cuenta me he
<lb n="9"/>impuesto en el
<choice>
<orig>Catalan</orig>
<reg>catalán</reg>
</choice>.
<lb n="10"/>
<choice>
<orig>Adios</orig>
<reg>Adiós</reg>
</choice>
<persName>Antonio</persName>. Saluda a tu padre.
<lb n="11"/>Y
<choice>
<orig>saludate tu</orig>
<reg>salúdate tú</reg>
</choice>
con mi mejor <hi rend="underline">inalterable</hi>
<lb n="12"/>amistad. ¡Has visto lo que han hecho con <persName>Paquito</persName>! (Silencio)
</p>
<closer>
<signed><persName>Federico</persName></signed>
</closer>
</div>
<div type="dirección">
<opener>
<address>
<addrLine>
<choice>
<abbr>
Sr<corr>.</corr>
</abbr>
<expan>Señor</expan>
</choice>
<choice>
<abbr>D.</abbr>
<expan>Don</expan>
</choice>
<persName>Antonio Luna</persName>
</addrLine>
<addrLine>
Acera de <unclear>Dairo</unclear> 62
</addrLine>
<addrLine>
<placeName>Granada</placeName>
</addrLine>
</address>
</opener>
</div>
<div type="estampillas">
<ab>
<stamp>Tarjeta Postal</stamp>
<stamp>Correspondencia</stamp>
<stamp><unclear>Barcelona</unclear></stamp>
<stamp><gap/></stamp>
</ab>
</div>
</body>
</text>
</TEI>
Aunque VS Code y BaseX nos dicen que nuestro código es sintácticamente válido en XML, podemos verificar que también es semánticamente válido en TEI con ayuda del TBE Validation Service:
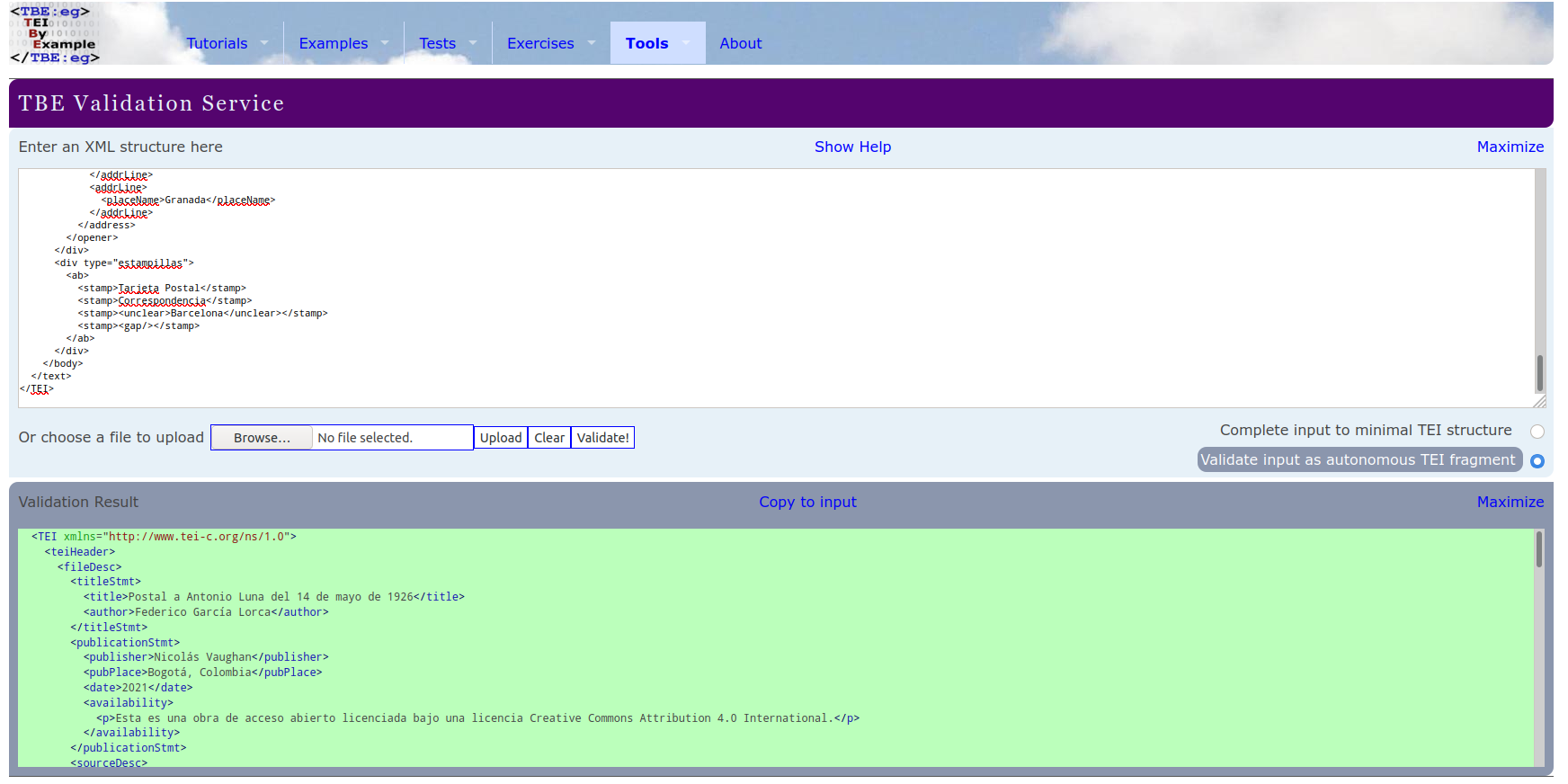
Validación TEI del código de la postal en TBE Validation Service. El color verde indica que la validación fue exitosa. Si hubiese algún error, aparecería un mensaje en color rojo.
Segundo ejemplo
Para nuestro segundo ejemplo hemos escogido un fragmento manuscrito del Pequeño manual del estudiante de historia universal (sin fecha), de la escritora colombiana Soledad Acosta de Samper (1833-1913). Este fragmento es muy interesante para nuestros fines, pues introduce notas y correcciones, entre otros rasgos textuales. Como veremos, TEI nos permite trabajar con todos ellos.
La imagen de la página 59 (disponible libremente en la Biblioteca Digital Soledad Acosta de Samper) es la siguiente:

Imagen del manuscrito ‘Pequeño manual del estudiante de historia universal’ de Soledad Acosta de Samper, tomo 1, p. 59
El <teiHeader>
En este caso el <teiHeader> de nuestro documento será el siguiente:
<teiHeader>
<fileDesc>
<titleStmt>
<title>Pequeño manual del estudiante de historia universal, tomo 1, p.59</title>
<author>Soledad Acosta de Samper</author>
</titleStmt>
<publicationStmt>
<publisher>Nicolás Vaughan</publisher>
<pubPlace>Bogotá, Colombia</pubPlace>
<date>2021</date>
<availability>
<p>Esta es una obra de acceso abierto licenciada bajo una licencia Creative Commons Attribution 4.0 International.</p>
</availability>
</publicationStmt>
<sourceDesc>
<biblStruct>
<monogr>
<author>Soledad Acosta de Samper</author>
<title>Pequeño manual del estudiante de historia universal, tomo 1, p.59</title>
<imprint>
<pubPlace>Sin lugar</pubPlace>
<date>Sin fecha</date>
</imprint>
</monogr>
<ref target="https://soledadacosta.uniandes.edu.co/items/show/408"/>
</biblStruct>
</sourceDesc>
</fileDesc>
</teiHeader>
Como solo hemos codificado un página para este ejercicio, la hemos indicado explícitamente en los metadatos de nuestro documento.
Si quisiéramos codificar todo el texto de Soledad Acosta, no sería necesario explicitar dicha información.
Por otro lado, puesto que nuestro texto objeto es un manuscrito cuyo lugar y fecha de elaboración nos son desconocidos, debemos dejar eso claro en el <sourceDesc>.
El <text>
Con respecto al cuerpo del texto —que se encuentra contenido en el elemento <text> del documento, como ya hemos visto—, lo primero que haremos será identificar los tipos de texto según su función estructural.
A primera vista podemos hallar ocho tipos básicos, ilustrados con colores y números en la siguiente imagen:

Análisis de la p.59
Los textos son los siguientes:
- Nota marginal
- Título (encabezado) de la sección
- Paginación
- Texto principal
- Corrección (dentro del texto principal)
- Cita (dentro de la corrección)
- Nota a pie explicatoria (con referencia bibliográfica)
- Nota a pie bibliográfica
Podemos ver que los textos 1, 7 y 8 son notas textuales —la primera marginal, las otras dos a pie de página— y están en cierto modo “ancladas” en los textos que anotan. Eso significa que aunque visualmente puedan parecer desarticulados y separados del texto principal (textos 4, 5 y 6), estructuralmente hablando los tres forman parte de él. De nuevo, su representación visual —esto es, su diseño gráfico en la composición de la página— es independiente de su función y categoría estructural con respecto al texto.
La paginación (texto 3)
En nuestro texto podemos distinguir dos formas de paginación. La primera es la “visual”, esto es, los números 47 y 59 que aparecen escritos —por manos diferentes— en la esquina superior derecha de la página. Es probable que el número 47 corresponda a una primera paginación del manuscrito hecha por la autora misma, y que el número 59 corresponda a una paginación posterior hecha quizás por la Biblioteca Nacional de Colombia (o por algún propietario/lector anterior del manuscrito).
La segunda forma de paginación es la lógica (o estructural), esto es, el puesto que la página o folio ocupa en la secuencia ordenada del texto completo del manuscrito. Si examinamos el PDF del manuscrito completo, podemos ver que la paginación lógica parece coincidir en líneas generales con la del segundo número de la paginación visual (59, en nuestro caso).Vale notar que la Biblioteca Nacional de Colombia ha eliminado del PDF las páginas en blanco, seguramente para reducir su tamaño.
Ahora bien, hay editores/codificadores —con quienes yo estoy de acuerdo— que consideran innecesario incluir explícitamente la primera forma de paginación, debido a que por lo general esta solo cumple una función estructural y por lo tanto ya se halla explícitamente incluida en la segunda.
(Del mismo modo que el subrayado puede indicar un rasgo estructural y por lo tanto no ha de codificarse por separado con un elemento <hi @rend="underline">, por ejemplo.)
En aras de la exhaustividad codificaremos ambas paginaciones para este ejemplo.
Para la primera usaremos dos elementos <ab>4 dentro de un elemento <div> que los incluye juntos; para la segunda usaremos el hito <pb/> (“page break”, salto de página) con el atributo @n="59":
<body>
<pb n="59"/>
<div>
<ab>47</ab>
<ab>59</ab>
</div>
<!-- aquí continúa el resto del texto -->
</body>
Vamos a poner el hito <pb/> justo al principio de la página, porque de lo contrario indicaríamos que los números (aquellos dos escritos por distintas personas) están en la página anterior.
TEI tiene diversas formas para indicar la identidad de las personas que escriben un documento.
En crítica textual se las denomina “manos” cuando se trata de un texto manuscrito.
Podemos usar el atributo @hand en muchos de los elementos de TEI para hacer explícita esta responsabilidad.
En el caso de los números de página, claramente hay dos manos involucradas. Podemos codificarlas así:
<ab hand="#SAS">47</ab>
<ab hand="#BNC">59</ab>
El signo de numeral (#) significa que estamos haciendo referencia a un valor previamente definido.
Esta es la manera de codificar manos en TEI usando el atributo @hand. El signo de numeral # significa que estamos haciendo referencia a un valor previamente definido.
Aunque aún no hayamos definido a qué se refieren SAS y BNC (hemos usado las siglas de “Soledad Acosta de Samper” y “Biblioteca Nacional de Colombia”, suponiendo que ellos sean los responsables), por ahora queda claro al menos que se trata de dos “manos” diferentes.
En otro lugar de nuestro documento TEI podemos definir esas referencias, usando el elemento listPerson (“list of persons”, lista de personas).
Un buen lugar para hacerlo es dentro de un tercer hijo de <TEI> entre <teiHeader> y <text>: el elemento standOff, por ejemplo:
<?xml version="1.0" encoding="UTF-8"?>
<TEI xmlns="http://www.tei-c.org/ns/1.0">
<teiHeader>
<!-- metadatos del texto -->
</teiHeader>
<standOff>
<listPerson>
<person xml:id="SAS">
<persName>Soledad Acosta de Samper</persName>
</person>
<person xml:id="BNC">
<name>Biblioteca Nacional de Colombia</name>
</person>
</listPerson>
</standOff>
<text xml:lang="spa" hand="#SAS">
<body>
<!-- cuerpo del texto -->
</body>
</text>
</TEI>
El atributo @hand, cuyos valores son #SAS y #BNC respectivamente, en últimas se refiere a los dos elementos <person> (previamente definidos dentro del elemento <listPerson>) por medio de los atributos genéricos de XML @xml:id.
Como dijimos arriba, XML requiere que los valores de @xml:id sean únicos.
Puesto que la Biblioteca Nacional de Colombia es una institución y no una persona, debemos usar el elemento <name> en lugar del elemento <persName>.
Asimismo, si quisiéramos incluir información adicional sobre ellos (años de nacimiento y de muerte, ocupación, localización geográfica, etcétera) podríamos hacerlo dentro del elemento <person>.
Finalmente, nótese que hemos decidido incluir el atributo @hand="#SAS" en el elemento <text>, a fin de identificar a Soledad Acosta como la persona que escribió de su puño y letra el manuscrito que estamos codificando.
El texto principal (textos 2, 4, 5 y 6)
Los textos 4, 5 y 6 forman parte de una sección que empieza en esta página, siendo el texto 2 su encabezado.
Vamos a usar el elemento <head> (encabezado) para codificarlo.
Sin embargo, lo haremos dentro de un <div> que contenga el resto del texto principial.6
Empecemos entonces transcribiendo el manuscrito en este punto:
<div>
<lb n="1"/><head>4</head>
<p>
<lb n="2"/>Misterio de la Historia de la humanidad
<lb n="3"/>antes del Diluvio universal, puesto que el histor
<lb n="4" break="no"/>riador *reconocido* más antiguo —<persName>Moisés</persName>— encierra todo
<lb n="5"/>aquel tiempo transcurrido <unclear>enteros</unclear> cortos acá
<lb n="6"/>justos. Se ha calculado que solo duró 1659 a
<lb n="7" break="no"/>ños, <choice><orig>segun</orig><reg>según</reg></choice> unos y 2,000 según otros. Como los
<lb n="8"/>hombres gozaban de una longevidad extra
<lb n="9" break="no"/>ordinaria (1) naturalmente alcanzaban <choice><orig>á</orig><reg>a</reg></choice> per
<lb n="10" break="no"/>feccionarse muchísimo, y como sus <unclear>conveinen
<lb n="11" break="no"/>tas</unclear> fueron asombrosas<corr>,</corr> se llenaron de soberbia, y
<lb n="12"/>esa soberbia se convirtió en corrupción y esta
<lb n="13"/>en completa perversión, leemos en el <title>Génesis</title> (1)
<lb n="14"/>"Y había gigantes sobre la tierra en aque
<lb n="15" break="no"/>llos días .... poderosos desde la <choice><orig>antigue</orig><reg>antigüe</reg></choice>
<lb n="16" break="no"/>dad, varones de fama ... Y viendo Dios que
<lb n="17"/>era mucha la malicia de los hombres,
<lb n="18"/>y que todos los pensamientos del corazón<sic>,</sic>
<lb n="19"/>eran inclinados al mal en todo tiempo, y entonces
</p>
</div>
Varias cosas deben señalarse sobre esta primera versión.
Primero, hemos incluido el hito <lb n="1"/> antes del encabezado, puesto que este hace parte del texto principal y es una línea que debe contarse.
Segundo, hemos codificado con el elemento <persName> el nombre propio “Moisés”, y con el elemento <title> el título del Génesis.
Tercero, cuando hay una ruptura de palabra al final de la línea no debemos escribir un guión (-).
En ese caso debemos usar el atributo @break="no" en el siguiente salto de línea, para indicar que la palabra no se rompe ahí sino que continúa en la siguiente línea del texto.
Esto ocurre en las líneas 4, 7, 9, 10, 11, 15 y 16.
Cuarto, en la línea 11 hemos incluido una coma (con <corr>,</corr>) y en la línea 18 hemos señalado que hay una coma que sobra (usando el elemento <sic>, así: <sic>,</sic>). Ambas son intervenciones editoriales debidamente codificadas.
Quinto, en las líneas 5 y 10-11 hay unas palabras que no hemos entendido bien.
Las hemos incluido dentro de dos elementos <unclear>. Nótese de paso la utilidad del elemento de autocerrado <lb/> en la línea 11: nos permite encerrar la palabra “coveinentas” en un elemento <unclear> sin violar las reglas sintácticas de XML.
Sexto, hemos usado temporalmente unos asteriscos en la línea 4 para indicar una corrección hecha por la autora misma; de hecho, la caligrafía parece ser la misma en la corrección y en el texto principal, por lo que es muy probable que ambas sean de la autora.
TEI nos permite codificar estas correcciones con el elemento <add> (“addition”, adición), que indica que el texto contenido en él es un añadido introducido a modo de corrección en el texto objeto, y no una corrección editoral nuestra, que como sabemos se codifica con el elemento <corr>.
Usaremos el atributo @place="arriba" para señalar su ubicación en el manuscrito.
Así pues, la línea 4 quedaría así en una nueva versión del documento:
<lb n="4" break="no"/>riador <add place="arriba">reconocido</add> más antiguo —<persName>Moisés</persName>— encierra todo
Correcciones
Nótese que entre las líneas 3 y 4 la palabra “historiador” parece ser una corrección o enmienda.
La autora parece haber borrado algo en lápiz y luego haberlo corregido con esa palabra.
Como no podemos descifrar qué palabra ha sido borrada, debemos usar el elemento de autocerrado <gap/>, con los atributos @quantity="1" y @unit="palabra" para codificar eso.
Dicho elemento señala que hay una laguna textual.
Ahora bien, para indicar que hay una corrección en la que un texto ha sido eliminado y otro ha sido introducido usamos los elementos <del> (“deletion”, eliminación) y <add>, encerrados juntos en un elemento <subst> (“substition”, sustitución), que indica una sustitución:
<subst>
<del>texto eliminado</del>
<add>texto añadido</add>
</subst>
En consecuencia, las líneas 3 y 4 quedarían así en una nueva versión de la codificación:
<lb n="3"/>antes del Diluvio universal, puesto que el <subst><del><gap quantity="1" unit="palabra"/></del><add>histo
<lb n="4" break="no"/>riador</add></subst> <add place="arriba">reconocido</add> más antiguo —<persName>Moisés</persName>— encierra todo
Recuérdese que los saltos de línea en XML, así como el sangrado, no es semánticamente significativo, sino que solo se usa para la legibilidad de las personas que leen el texto.
La línea 4 aparece sangrada simplemente para indicar que su inicio (riador</add>) está contenido en el elemento <subst>, que inicia en la línea anterior.
Para el computador —más precisamente para el procesador de XML— estos sangrados y saltos de línea son irrelevantes.
Las líneas 13-19 son una corrección hecha por la autora.
Ella recortó una hoja de su cuaderno con la corrección y la pegó sobre la hoja de esta página.
En consecuencia codificaremos esas líneas dentro de un elemento <subst>:
<subst>
<del>
<gap quantity="7" unit="líneas" reason="ilegible"/>
</del>
<add>
<lb n="13"/>en completa perversión, leemos en el <title>Génesis</title> (1)
<lb n="14"/>"Y había gigantes sobre la tierra en aque
<lb n="15" break="no"/>llos días .... poderosos desde la <choice><orig>antigue</orig><reg>antigüe</reg></choice>
<lb n="16" break="no"/>dad, varones de fama ... Y viendo Dios que
<lb n="17"/>era mucha la malicia de los hombres,
<lb n="18"/>y que todos los pensamientos del corazón<sic>,</sic>
<lb n="19"/>eran inclinados al mal en todo tiempo, y entonces
</add>
</subst>
Hemos indicado con el elemento <gap/> que ignoramos el contenido del texto eliminado.
Con los atributos @quantity="7" y @unit="líneas" indicamos su extensión.
Y hemos añadido finalmente una explicación con el atributo opcional @reason="ilegible".
Citas
Entre las líneas 14 y 19 tenemos una cita del libro del Génesis. De hecho, la cita se extiende a la siguiente página del manuscrito, aunque para los fines de este ejemplo supondremos que termina acá. Para codificarla tenemos a nuestra disposición dos posibilidades. La más simple es usar el elemento <q> (“quoted”, citado), para indicar que hay un texto entre comillas (nótese que hemos eliminado los signos de ", pues estos cumplen estructuralmente la misma función realizada por <q>).
Sería entonces algo como esto:
<lb n="14"/>
<q>
Y había gigantes sobre la tierra en aque
<lb n="15" break="no"/>llos días .... poderosos desde la <choice><orig>antigue</orig><reg>antigüe</reg></choice>
<lb n="16" break="no"/>dad, varones de fama ... Y viendo Dios que
<lb n="17"/>era mucha la malicia de los hombres,
<lb n="18"/>y que todos los pensamientos del corazón<sic>,</sic>
<lb n="19"/>eran inclinados al mal en todo tiempo, y entonces
</q>
La segunda posibilidad es un poco más sofisticada.
Podemos usar el elemento <cit> (“citation”, citación)
para crear una citación que incluya el texto citado (dentro de un elemento <quote>(cita)) y una referencia bibliográfica (dentro de un elemento <bibl> (“bibliographic citation”, citación bibliográfica)).7
Su estructura es la siguiente:
<cit>
<quote>texto de la cita</quote>
<bibl>referencia bibliográfica de la cita</bibl>
</cit>
Notemos que —como en el caso del elemento <head> de arriba— tanto el texto de la cita (dentro de <quote>) como el de la referencia bibliográfica (dentro de <bibl>) deben efectivamente encontrarse en el texto.
Por fortuna, la autora nos ha proporcionado la información bibliográfica en una nota a pie de página (texto 8). En la siguiente sección discutiremos cómo aclarar que se trata de, además de una cita, de una nota a pie de página. Sin embargo, antes de hacerlo, notemos que debemos corregir “Genesis” por “Génesis”, haciendo uso de los elementos <sic> y <corr>, dentro de un elemento <choice>, tal como lo hicimos anteriormente:8
<choice>
<sic>Genesis</sic>
<corr>Génesis</corr>
</choice>
Podríamos entonces codificar la citación así:
<lb n="14"/>
<cit>
<quote>
Y había gigantes sobre la tierra en aque
<lb n="15" break="no"/>llos días .... poderosos desde la <choice><orig>antigue</orig><reg>antigüe</reg></choice>
<lb n="16" break="no"/>dad, varones de fama ... Y viendo Dios que
<lb n="17"/>era mucha la malicia de los hombres,
<lb n="18"/>y que todos los pensamientos del corazón<sic>,</sic>
<lb n="19"/>eran inclinados al mal en todo tiempo, y entonces
</quote>
<bibl>
<title>
<choice>
<sic>Genesis</sic>
<corr>Génesis</corr>
</choice>
</title>
Cap. IV<corr>,</corr> ver 4, 5, 6, 7
</bibl>
</cit>
Nótese la coma que hemos introducido por medio de un elemento <corr> para separar el capítulo de los versículos. La ventaja de esta manera más exhaustiva de codificar las citaciones es que hemos vinculado semánticamente la cita con su referencia bibliográfica, independientemente de cómo haya sido representada visualmente.
Notas textuales (textos 1, 7 y 8)
Como dijimos arriba, en este fragmento del texto manuscrito tenemos tres notas:
una marginal (margen izquierdo) y dos a pie de página (margen inferior).
TEI cuenta con el elemento <note> para codificar toda clase de notas textuales.
Este elemento tiene una variedad de atributos para especificar el tipo de la nota, su función, ubicación, responsable, etcétera.
Los más importantes para nuestro caso serán estos:
@type, el tipo de la nota; para nuestros ejemplo, sus valores podrán serestructural,aclaratoriaybibliográfica@place, el lugar de ubicación:margen-izquierdoymargen-inferioren nuestro caso
El valor estructural para el atributo @type de la nota significa que esta sirve para indicar la estructura del texto; en este caso el contenido será “La historia antes del Diluvio”.
Es evidente que no es una nota aclaratoria, sino que sirve casi como encabezado del texto principal (textos 4, 5 y 6).
Nota estructural (texto 1)
Su código será el siguiente:
<note type="estructural" place="margen-izquierdo">
La historia antes del Diluvio
</note>
Cabe destacar que no hemos encerrado el texto en un elemento <div>.
¿Dónde lo pondremos en nuestro documento, entonces?
Vamos a considerar que se trata de una nota marginal estructural con respecto a toda la sección y, así, irá ubicada al principio de esta manera:
<div>
<lb n="1"/><head>4</head>
<p>
<note type="estructural" place="margen-izquierdo">
La historia antes del Diluvio
</note>
<lb n="2"/>Misterio de la Historia de la humanidad
<!-- aquí continua el resto del texto -->
</p>
</div>
Es importante aclara aquí que, aunque en el manuscrito este texto aparezca separado por guiones —ya que de lo contrario no cabría en el margen—, para nosotros esta partición no es significativa. La razón de esto es que dicha partición no constituye en sí misma saltos de línea (análogos a los del texto principal). En general, la convención es no codificar los saltos de línea de los textos periféricos —notas marginales, notas a pie de página—, sino solo los del texto principal en la página. Con todo, nada en TEI impide que codifiquemos cada línea en una superficie textual.
Nota aclaratoria (texto 7)
La segunda nota está anclada en la línea 9 del texto, luego de la palabra “extraordinaria”. En el manuscrito hay un llamado a pie de página: “(1)”. Podemos eliminarlo de nuestra codificación, puesto que su función es puramente estructural. Así pues, el código será el siguiente:
<lb n="9" break="no"/>ordinaria
<note type="aclaratoria" place="margen-inferior">
Los años de <persName>Mathusalem</persName> fueron 965 y los de <persName>Lamech</persName> 777.
(<bibl>
<title>
<choice>
<sic>Genesis</sic>
<corr>Génesis</corr>
</choice>
</title>
Cap. V, ver. 27-29
</bibl>)
</note>
Como puede verse, hemos incluido los nombres “Mathusalem” y “Lamech” en sendos elementos <persName>.
Más interesante es el uso del elemento <bibl> para introducir “información bibliográfica ligeramente estructurada (“loosely-structured”)”, como lo define la documentación de TEI.9
Dentro del elemento <bibl> tenemos dos hijos: un elemento <title>, que codifica el título de una obra (en este caso “Génesis”, título que hemos normalizado a partir de “Genesis” en el manuscrito), y un texto: “Cap. V, ver. 27-29” que dejamos tal cual aparece.
Como puede verse, todo el <bibl> va entre paréntesis, exactamente como aparece en el manuscrito de la autora.10
Nota bibliográfica (texto 8)
Como vimos antes, la autora nos ha proporcionado amablemente la información bibliográfica para la cita del Génesis contenida en las líneas 14-19.
Esa información está en una nota a pie de página.
Lo que haremos ahora es incluir el elemento <bibl> de la citación en un elemento <note>.
El código de toda la citación será entonces el siguiente:
<lb n="14"/>
<cit>
<quote>
Y había gigantes sobre la tierra en aque
<lb n="15" break="no"/>llos días .... poderosos desde la <choice><orig>antigue</orig><reg>antigüe</reg></choice>
<lb n="16" break="no"/>dad, varones de fama ... Y viendo Dios que
<lb n="17"/>era mucha la malicia de los hombres,
<lb n="18"/>y que todos los pensamientos del corazón<sic>,</sic>
<lb n="19"/>eran inclinados al mal en todo tiempo, y entonces
</quote>
<note type="bibliográfica" place="margen-inferior">
<bibl>
<title>
<choice>
<sic>Genesis</sic>
<corr>Génesis</corr>
</choice>
</title>
Cap. VI<corr>,</corr> ver. 4, 5, 6, 7
</bibl>
</note>
</cit>
Código completo del documento
El código completo del documento TEI del fragmento de Soledad Acosta es este:
<?xml version="1.0" encoding="UTF-8"?>
<TEI xmlns="http://www.tei-c.org/ns/1.0">
<teiHeader>
<fileDesc>
<titleStmt>
<title>Pequeño manual del estudiante de historia universal, tomo 1, p.59</title>
<author>Soledad Acosta de Samper</author>
</titleStmt>
<publicationStmt>
<publisher>Nicolás Vaughan</publisher>
<pubPlace>Bogotá, Colombia</pubPlace>
<date>2021</date>
<availability>
<p>Esta es una obra de acceso abierto licenciada bajo una licencia Creative Commons Attribution 4.0 International.</p>
</availability>
</publicationStmt>
<sourceDesc>
<biblStruct>
<monogr>
<author>Soledad Acosta de Samper</author>
<title>Pequeño manual del estudiante de historia universal, tomo 1, p.59</title>
<imprint>
<pubPlace>Sin lugar</pubPlace>
<date>Sin fecha</date>
</imprint>
</monogr>
<ref target="https://soledadacosta.uniandes.edu.co/items/show/408"/>
</biblStruct>
</sourceDesc>
</fileDesc>
</teiHeader>
<standOff>
<listPerson>
<person xml:id="SAS">
<persName>Soledad Acosta de Samper</persName>
</person>
<person xml:id="BNC">
<name>Biblioteca Nacional de Colombia</name>
</person>
</listPerson>
</standOff>
<text xml:lang="es" hand="#SAS">
<body>
<pb n="59"/>
<div>
<ab hand="#SAS">47</ab>
<ab hand="#BNC">59</ab>
</div>
<div>
<lb n="1"/><head>4</head>
<p>
<note type="estructural" place="margen-izquierdo">
La historia antes del Diluvio
</note>
<lb n="2"/>Misterio de la Historia de la humanidad
<lb n="3"/>antes del Diluvio universal, puesto que el <subst><del><gap quantity="1" unit="palabra"/></del><add>histo
<lb n="4" break="no"/>riador</add></subst> <add place="arriba">reconocido</add> más antiguo —<persName>Moisés</persName>— encierra todo
<lb n="5"/>aquel tiempo transcurrido <unclear>enteros</unclear> cortos acá
<lb n="6"/>justos. Se ha calculado que solo duró 1659 a
<lb n="7" break="no"/>ños, <choice><orig>segun</orig><reg>según</reg></choice> unos y 2,000 según otros. Como los
<lb n="8"/>hombres gozaban de una longevidad extra
<lb n="9" break="no"/>ordinaria
<note type="aclaratoria" place="margen-inferior">
Los años de <persName>Mathusalem</persName> fueron 965 y los de <persName>Lamech</persName> 777.
(<bibl>
<title>
<choice>
<sic>Genesis</sic>
<corr>Génesis</corr>
</choice>
</title>
Cap. V, ver. 27-29
</bibl>)
</note>
naturalmente alcanzaban <choice><orig>á</orig><reg>a</reg></choice> per
<lb n="10" break="no"/>feccionarse muchísimo, y como sus <unclear>conveinen
<lb n="11" break="no"/>tas</unclear> fueron asombrosas<corr>,</corr> se llenaron de soberbia, y
<lb n="12"/>esa soberbia se convirtió en corrupción y esta
<subst>
<del>
<gap quantity="7" unit="líneas" reason="ilegible"/>
</del>
<add>
<lb n="13"/>en completa perversión, leemos en el <title>Génesis</title> (2)
<lb n="14"/>
<cit>
<quote>
Y había gigantes sobre la tierra en aque
<lb n="15" break="no"/>llos días .... poderosos desde la <choice><orig>antigue</orig><reg>antigüe</reg></choice>
<lb n="16" break="no"/>dad, varones de fama ... Y viendo Dios que
<lb n="17"/>era mucha la malicia de los hombres,
<lb n="18"/>y que todos los pensamientos del corazón<sic>,</sic>
<lb n="19"/>eran inclinados al mal en todo tiempo, y entonces
</quote>
<note type="bibliográfica" place="margen-inferior">
<bibl>
<title>
<choice>
<sic>Genesis</sic>
<corr>Génesis</corr>
</choice>
</title>
Cap. VI<corr>,</corr> ver. 4, 5, 6, 7
</bibl>
</note>
</cit>
</add>
</subst>
</p>
</div>
</body>
</text>
</TEI>
Aunque VS Code nos dice que nuestro código es sintácticamente válido en XML, podemos verificar que también es semánticamente válido en TEI con ayuda del TBE Validation Service:
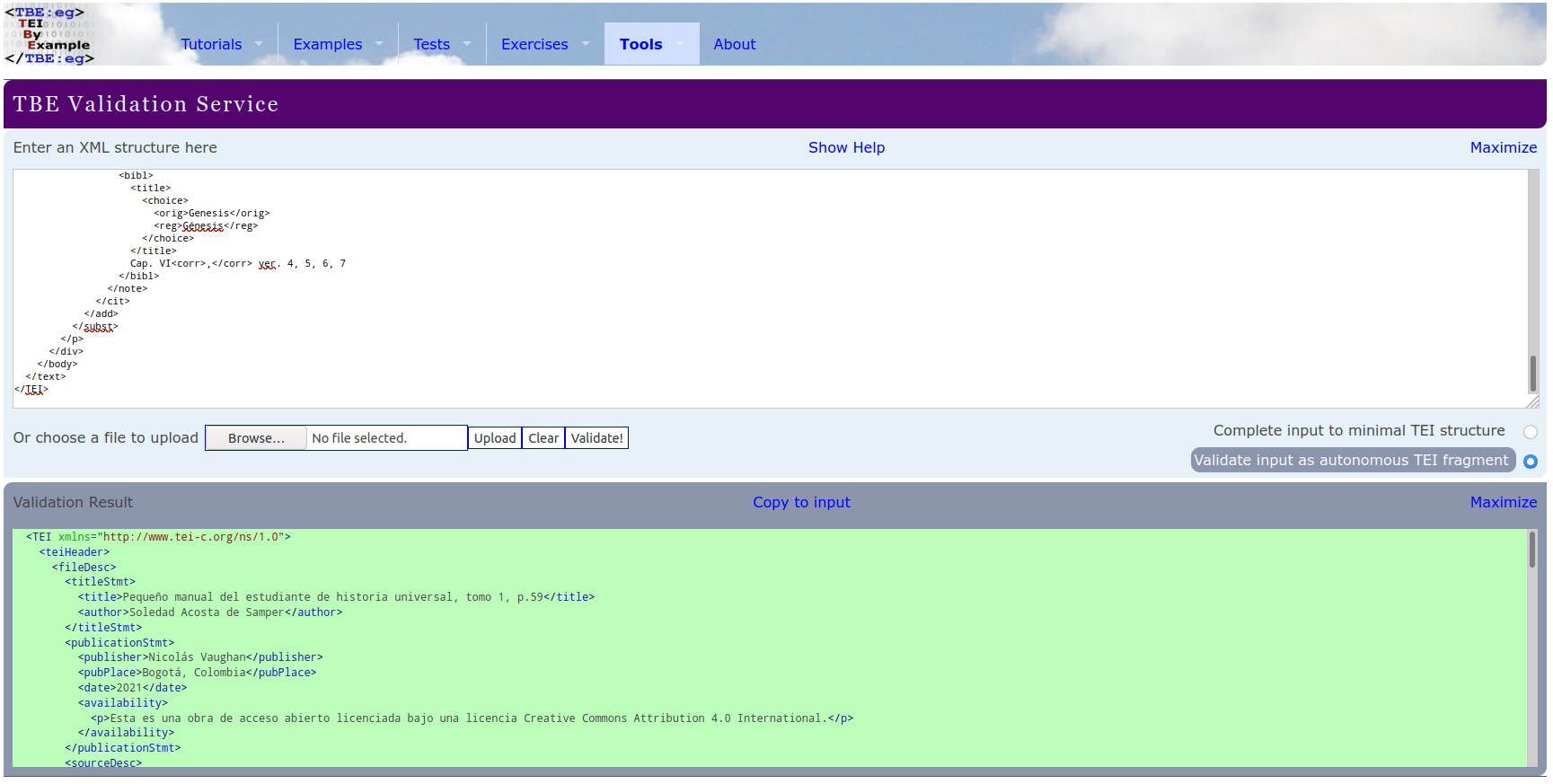
Validación TEI del código del manuscrito de Soledad Acosta en TBE Validation Service. El color verde indica que la validación fue exitosa. Si hubiese algún error, aparecería un mensaje en color rojo
Conclusiones
En esta segunda parte de la lección realizamos lo siguiente:
-
Pusimos en práctica la teoría vista en la primera parte
-
Estudiamos dos ejemplos de codificación al lenguaje de marcado TEI-XML: una postal y un manuscrito
-
Discutimos diferentes formas de aprovechar los elementos y atributos ofrecidos por TEI para codificar con precisión nuestros dos ejemplos
Lo anterior nos permitió ver las ventajas y posibilidades de TEI para describir y codificar diversos tipos de texto.
Epílogo. Transformaciones básicas sin XSLT
Ya hemos aprendido a codificar en TEI dos textos simples: una postal y el fragmento de un manuscrito con correcciones y notas. ¿Qué podemos hacer ahora con dichas codificaciones?
En su ingenuidad, esta pregunta puede parecer en principio injustificada. La codificación es un fin en sí mismo, en la medida en que constituye un ejercicio analítico sobre un texto. Es más, si recordamos las recomendaciones que hemos hecho repetidamente con respecto a distinguir entre marcado de visualización y marcado semántico, podría parecer desatinado preguntarse cómo podemos visualizar el resultado de nuestra codificación.
Sin embargo, también hay que saber que la codificación TEI es solo uno de los pasos en una cadena, probablemente muy extensa, de reutilización, procesamiento y análisis de textos con herramientas de las humanidades digitales.
En sí mismo, TEI no es más que un lenguaje de codificación de textos. En consecuencia, TEI nos permite mostrar, transformar, analizar, reutilizar y realizar un sin fin de procesos y procedimientos con los documentos codificados. Para eso precisamos de otros lenguajes y otras tecnologías, particularmente el lenguaje de transformaciones XSLT, al que aludimos líneas atrás. XSLT es un lenguaje altamente sofisticado cuya explicación no podemos cubrir en esta lección.
Existen herramientas gratuitas (y comerciales) que nos permiten transformar los documentos TEI en otros formatos. Entre ellas teiPublisher (con su extensión para VS Code) y CETEIcean, que permiten producir aplicaciones web basadas en HTML y CSS bastante elaboradas. La instalación y uso de estas dos herramientas supera los límites de este breve epílogo; sin embargo, próximamente Programming Historian publicará la tercera parte de esta serie, dedicada al uso de CETEIcean, escrita por Gabriel Calarco y Gimena del Río Riande.
Ahora bien, existe otra herramienta para realizar transformaciones llamada OxGarage, creada por el consorcio TEI. Podemos usar OxGarage en línea o también podemos instalarla localmente en nuestro computador. Para nuestros fines usaremos la versión en línea.
Antes de comenzar, debemos asegurarnos que nuestros documentos TEI sean sintáctica y semánticamente válidos, pues de lo contrario no podrán ser procesados por OxGarage, ni por ningún otro procesador. Para ello podemos usar una herramienta como la del TBE Validation Service, mencionada arriba.
Una vez abierta la página web de OxGarage, haremos clic en la opción “Documents”:
OxGarage: opción documentos
Luego seleccionaremos “TEI P5 XML Document” en la columna “Convert from”:
OxGarage: formato de entrada
Entonces nos aparecerá la columna de opciones para elegir el formato de salida, donde tenemos 19 posibilidades: LaTeX, ePub, DOCX, PDF, XHTML, etcétera. Para nuestro ejemplo escojeremos la opción “XHTML”:
OxGarage: formato de salida: xHTML
Ahora subiremos nuestro documento TEI al servidor, haciendo clic en el botón “Seleccionar archivo…” de la izquierda. Si nuestro documento hubiera incluido imágenes, por ejemplo en un facsímil digital, podríamos subirlas en un archivo .zip con el botón “Browse…” de la derecha.
OxGarage: subir el documento
Finalmente haremos clic en el botón “Convert” y esperaremos a que el servidor descargue el resultado en el navegador. Si nada sucede, es probable que exista un error en el documento TEI de entrada; desafortunadamente OxGarage no reporta dichos errores.
OxGarage: convertir
Hagamos la prueba primero con la postal y luego con el fragmento del manuscrito. Podemos abrir los archivos resultantes con extensión “.html” en cualquier navegador web, haciendo doble clic sobre ellos en el explorador de archivos. Este es el resultado de la transformación para el ejemplo de la postal:

OxGarage: XHTML resultante de la postal, abierto en el navegador Firefox
Nótese cómo los elementos <foreign> han sido representados en cursivas en el XHTML.11
Y este es el resultado de la transformación para la codificación del manuscrito:

OxGarage: xHTML resultante del manuscrito, abierto en el navegador Firefox
En este caso OxGarage ha usado paréntesis angulares (⟨⟩) para indicar los añadidos, incluido un [?] luego de las palabras dudosas (correspondientes a los elementos <unclear>).
Estos dos ejemplos de conversión pueden parecer algo simples. Ciertamente, el motor conversión de OxGarage realiza transformaciones XSLT muy elementales y genéricas. Con todo, OxGarage puede ser muy útil para extraer el texto de codificaciones de documentos extensos, para los cuales aún no hayamos programado transformaciones XSLT más elaboradas.
Referencias recomendadas
-
La documentación completa de TEI (los TEI Guidelines) está disponible en la página del consorcio: https://tei-c.org/guidelines/ . Si bien está dispónible en varios idiomas, solo está completa en inglés.
-
Una buena introducción a TEI es el libro ¿Qué es la iniciativa de codificación de textos? Cómo añadir marcado inteligente a los recursos digitales de Lou Burnard (Marsella: OpenEdition Press, 2012/2022) disponible gratuitamente en línea.
-
Un buen tutorial para XML está disponible en: https://www.w3schools.com/xml/ y en: https://www.tutorialspoint.com/xml/index.htm
-
El consorcio TEI también ofrece una buena introducción a XML: https://www.tei-c.org/release/doc/tei-p5-doc/en/html/SG.html
-
La documentación oficial de XML está disponible en la página del consorcio W3C: https://www.w3.org/XML/ También está disponible la documentación para toda la familia XSL (incluido XSLT): https://www.w3.org/Style/XSL/
-
La Mozilla Foundation también ofrece una buena página sobre XSLT y tecnologías asociadas: https://developer.mozilla.org/es/docs/Web/XSLT (en español) y https://developer.mozilla.org/en-US/docs/Web/XSLT (en inglés)
-
La página TTHUB contiene una excelente “Introducción a la Text Encoding Initiative” por Susanna Allés Torrent (2019): https://tthub.io/aprende/introduccion-a-tei/
-
En Programming Historian existe ya publicada una lección introductoria a XML y las transformaciones XSL: Transformación de datos con XML y XSL para su reutilización, de M. H. Beals.
Notas
De acuerdo con la documentación de TEI, <q> se usa en general para indicar que un texto se menciona y no se usa, lo cual usualmente se representa gráficamente poniendo el texto entre comillas o en cursivas. El elemento <quote>, por el contrario, se usa para atribuirle a alguien (a “un autor o narrador”) la autoría del texto. En ese sentido, cuando se codifica por completo una citación bibliográfica (con el elemento <cit>), en nuestra opinión es recomendable incluir en ella tanto el texto citado (en un elemento <quote>) como la referencia bibliográfica (en un elemento <bibl>).
-
Adoptaremos la convención de usar una
@para denotar en esta lección un atributo de un elemento de XML. Sin embargo, ese signo no se usa en el código de XML, sino solo en la documentación (como esta lección). Por ejemplo,@typesignifica el atributotypeen —digamos—<div type="recto">. ↩ -
Al respecto véase la primera lección. ↩ ↩2
-
Un “elemento de autocerrado” es un elemento de XML que no tiene contenido, por ejemplo:
<name></name>, que se abrevia así:<name/>. Nótese la barra invertida/antes del cierre de la etiqueta. Suelen usarse en TEI para los denominados elementos “hitos” (milestones), como los saltos de línea (<lb/>), saltos de página (<pb/>) y saltos de columna (<cb/>), que carecen de contenido y solo se usan para marcar un lugar preciso en el texto. Los procesadores de XML (como por ejemplo los navegadores web) automáticamente expanden estos elementos en su forma larga, de modo que son completamente sinónimos. ↩ ↩2 -
Hay quienes prefieren usar aquí el elemento
<ab>(anonymous block, “bloque anónimo”) en lugar del elemento<p>. Hacen eso porque consideran, no sin cierta razón, que este no es propiamente un párrafo sino un bloque genérico de texto. ↩ ↩2 -
Agradezco a David Merino Recalde por esta aclaración. Para nosotros esta distinción no será tan importante por ahora, por lo que usaremos tranquilamente un elemento
<p>. ↩ -
Es importante aclarar que el elemento
<header>contiene un texto que efectivamente aparece en el documento objeto y que funciona como encabezado en una división; en otras palabras, no es meramente una división lógica de este. Si quisiéramos —digamos en una edición crítica— introducir encabezados que no aparecen efectivamente el texto, sino que contienen un texto introducido por el editor, TEI ofrece el elemento<supplied>(“suplido”) para ello. Por ejemplo:<header><supplied>Argumentos en contra</supplied></header>.) ↩ -
La diferencia entre
<q>y<quote>quizá sea algo difusa. ↩ -
Otra opción sería usar los elementos
<orig>y<reg>, como lo hicimos antes con la postal, para indicar que estamos regularizando una variación ortográfica. La diferencia en últimas una decisión editorial, dependiendo de cómo se interprete la anomalía en el texto original: o bien como un error ortográfico de la autora (quien debió haber usado la tilde), o bien como una variante ortográfica. ↩ -
Si quisiéramos introducir una bibliografía completamente estructurada, por ejemplo en el caso de una edición crítica, podríamos utilizar el elemento
<biblStruct>(structured bibliographic citation, “citación bibliográfica estructurada”). ↩ -
Si para nuestros propósitos fuera importante codificar los números de llamado a nota (p. ej. “(1)”, “(2)”, etcétera), podríamos utilizar el elemento
<metamark>de TEI. Su uso es un poco más complicado, pues requiere referencias cruzadas (con el signo#, como vimos arriba). Sería algo como lo siguiente:<lb n="9" break="no"/>ordinaria <metamark target="#nota1">(1)</metamark> <note xml:id="nota1" type="aclaratoria" place="margen-inferior"> <!-- aquí va el texto de la nota --> </note>Esto podría ser importante si —por ejemplo— quisiéramos indicar que no existe claridad con respecto a la ubicación de los “llamados” a pie de página que anclan las notas (si la numeración no es clara, o si hay un número distinto de “llamados” y de notas, por ejemplo). Sin embargo, no haremos eso en la versión final de nuestro documento. ↩
-
Más exactamente, OxGarage los transformó en elementos
<span class="foreign">que, de acuerdo con el CSS vinculado en el documento xHTML tienen la propiedadfont-style:italic. En ese sentido, si un lector competente en CSS lo quisiera, podría asignarle otras propiedades CSS a este u otros elementos resultantes de la conversión. Sin embargo, esto no es necesario para producir un resultado relativamente agradable. ↩